
BCDR - Das Notfall-Rechenzentrum aus der Cloud Teil 2
Im ersten Teil unserer Blogserie zum Thema BCDR – Das Notfallrechenzentrum aus der Cloud haben wir Ihnen den Dienst „Azure Site Recovery“ und dessen Vorzüge vorgestellt. Im zweiten Teil zeigen wir Ihnen erste Schritte zur Nutzung des Dienstes und geben Ihnen Hinweise, sowie Tipps & Tricks mit auf den Weg.
Starten Sie mit der richtigen Strategie
Im Rahmen Ihrer BCDR-Strategie sollten Sie am Anfang Ihre gewünschten RPOs und RTOs für Ihre Business Applikationen festlegen.
Hier empfiehlt es sich tatsächlich für jede einzelne Business Applikation den Impact zu bewerten und RPOs und RTOs in verschiedene Klassen einzuteilen. Die entsprechenden Klassen sollten dann unterschiedliche Zielwerte für die RPOs und RTOs enthalten. Bei einer Verallgemeinerung besteht die große Gefahr, dass Sie hier unnötig teure BCDR-Strategien aufbauen.

So bereiten Sie die Nutzung der Azure Site Recovery vor
Eine gute Vorbereitung entscheidet oftmals über Erfolg und Misserfolg von Projekten. Zur Vorbereitung beim Einsatz des „Azure Site Recovery“-Dienstes sollten Sie mindestens folgende Punkte überprüfen:
- Netzwerkanforderungen
Für die Funktion der Services ist selbstverständlich, dass Daten ausgetauscht werden müssen. Entsprechend gibt es Anforderungen an Ihre Netzwerkanforderungen.
Der Datentransport erfolgt über den Port 9443 und die Orchestrierung über den Port 443.
Weiterhin sollten Sie darauf achten, dass der Konfigurationsserver im VMware den NIC-Typ VMXNET3 bekommt.
Natürlich sind auch unterschiedlichste URL-Freigaben notwendig. Diese können Sie der Dokumentation des Dienstes entnehmen.
- Überprüfung der Azure-Kontoberechtigung
Sollten Sie nicht der Abonnement-Administrator Ihrer Azure-Umgebung sein, sollten Sie sicherstellen, dass Sie mindestens folgende Rollen besitzen:
· Virtual Machine Contributor
· Site Recovery Contributor
Nach diesen Vorbereitungen sollten Sie das notwendigste getan haben, um mit den ersten Schritten beginnen zu können.

- Vorbereiten von Azure Site Recovery
Um mit der Einrichtung zu starten, erstellen Sie als erstes ein Recovery Services Vault.
Bei der Erstellung wählen Sie hierfür Ihre Subscription aus und legen entweder eine dedizierte Ressourcengruppe an oder verwenden eine bereits vorhandene. Als letztes müssen Sie sich noch für eine Region entscheiden. Weiterhin benötigen Sie ein virtuelles Azure Netzwerk. Hier empfiehlt es sich selbstredend die gleichen Paramater (Subscription, Ressourcengruppe, Region) zu wählen, wie im vorherigen Schritt.
- Lokales Vorbereiten von VMWare
„Azure Site Recovery“ benötigt mindestens ein Konto mit Leseberechtigung auf Ihrer VMWare-Umgebung, um die virtuellen Maschinen automatisch ermitteln zu können.
Für die Orchestrierung der Replikation, des Failovers und des Failbacks benötigt der Azure Site Recovery Service zusätzlich noch die Berechtigung Vorgänge, wie das Erstellen und Entfernen von Datenträgern, sowie das Einschalten virtueller Computer durchzuführen.
Es empfiehlt sich hierfür ein extra Konto auf vCenter-Ebene mit entsprechendem Namen.
Die entsprechenden notwendigen Berechtigungen können Sie dieser Tabelle entnehmen.
- Vorbereiten eines Kontos für die Installation des Mobility Services
Der sog. Mobilitätsdienst muss auf allen (virtuellen) Servern installiert werden, die Sie replizieren möchten. Am einfachsten erledigen Sie dies über eine Pushinstallation. Dies kann bei der Aktivierung von „Azure Site Recovery“ für die Server ausgeführt werden.
Hierfür benötigen Sie einen entsprechend berechtigten User.
Sie haben die Wahl einen Domänen-User zu nutzen, der dies dann entsprechend auf allen Domänen-Servern durchführen kann oder Sie nutzen einzelne lokale User.
Für virtuelle Linux-Computer muss ein entsprechender Superuser angelegt sein.
- Architektur für die Notfall-Wiederherstellung
Wenn Sie all die vorangegangen Vorbereitungen getroffen haben, können Sie nun starten und die notwendigen Server installieren, die Ihre Umgebung künftig absichern sollen.
Je nachdem, welchen Hypervisor Sie einsetzen oder ob Sie auch oder ausschließlich physische Server absichern wollen, unterscheiden sich die Architekturen für die Notfall-Wiederherstellung.
Die folgende Grafik zeigt die Referenzarchitektur der Microsoft für die Wiederherstellung von VMWare Maschinen und physischen Servern.
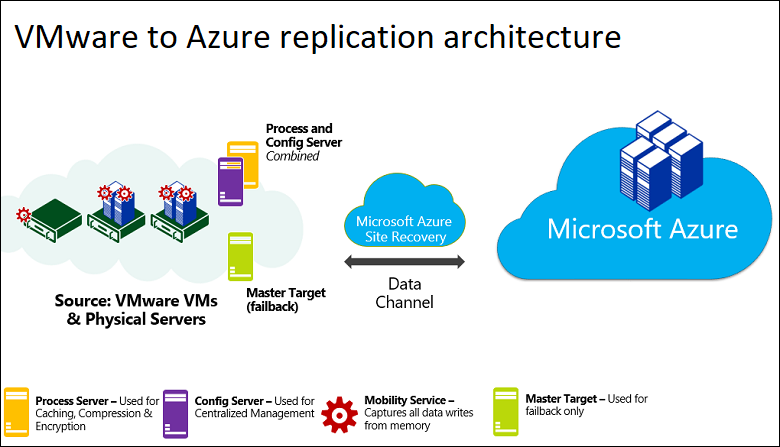
Referenzarchitektur der Microsoft für die Wiederherstellung von VMWare Maschinen und physischen Servern, Quelle: Microsoft DE
Der Konfigurationsserver (lila) koordiniert die Kommunikation zwischen der lokalen Umgebung und Azure und verwaltet die Datenreplikation.
Der Prozessserver (orange), der im Standard oftmals mit auf dem Konfigurationsserver installiert wird, empfängt die Replikationsdaten, optimiert diese durch Zwischenspeicherung, komprimiert und verschlüsselt diese und sendet sie an den Azure Storage. Weiterhin ist der Server für die Installation der „Azure Site Recovery“ Mobility Services auf den virtuellen Maschinen, die Sie replizieren möchten, zuständig. Zusätzlich führt er auf lokalen Computern eine automatische Ermittlung durch. Je nach Größe Ihrer Umgebung empfiehlt es sich mehrere Prozess-Server zu installieren, um größere Mengen von Replikations-Datenverkehr zur bewältigen.
Der Masterzielserver (grün), welcher ebenfalls im Standard mit auf dem Konfigurationsserver installiert wird, verarbeitet die Replikationsdaten während eines Failbacks von Azure. Ebenso, wie beim Prozess-Server, sollte bei größeren Umgebungen ein weiterer Masterzielserver verwendet werden.
Um die optimale Notfall-Wiederherstellungsarchitektur zu finden, stellt Microsoft mit dem Azure Site Recovery-Bereitstellungsplaner eine gute Unterstützung zur Verfügung.
Eine OVA-Datei zur Bereitstellung der unterschiedlichen Serverrollen finden Sie hier.
Fazit
Kurz zusammengefasst haben Sie nun all die notwendigen Schritte erledigt, um einen ersten Failover-Plan zu erstellen und stehen somit kurz davor Ihre Umgebung abzusichern. Hierfür kommt es vor allem auf das Routing an. Wie Sie aber auch erkennen konnten, ist der Aufwand „Azure Site Recovery“einzurichten bis hierhin überschaubar. Je nach Komplexität Ihrer Umgebung und ggf. „hart“ programmierten IP-Adressen innerhalb Ihrer Applikationen, kann sich der Aufwand auch bei „Azure Site Recovery“ in den Folge-Aktivitäten noch vergrößern. Dennoch stehen aus unserer Sicht das schnelle Voranschreiten und die reine Softwarelösungen definitiv auf der Haben-Seite dieser BCDR-Möglichkeit und ist damit auch unsere Empfehlung für Sie.

Ihr Ansprechpartner
Sie haben Fragen zu diesem Thema, möchten nähere Informationen und suchen einen Experten, der Ihnen weiterhilft?
Kontaktieren Sie uns! Wir freuen uns auf eine erfolgreiche Zusammenarbeit mit Ihnen.

Unsere Partner
Alle Partner





