
BCDR – The emergency data centre from the cloud
In our first part on the blog-series "Business Continuity and Disaster Recovery Management" we would like to give you a solution recommendation. It is important for us to explain the difference between backup/recovery and business continuity.
Modern IT services require high performance in the data centre in terms of stability and agility. Even planned processes, such as the maintenance of systems or migration projects, can paralyse regular operations. However, the continuity of IT services from the company should be ensured in any case. This is where the concept of "Business Continuity and Disaster Recovery Management" (BCDR) comes into play.
Downtime of the data centre as short as possible
In our experience, many companies have a very good handle on the typical and usually well-implemented topic of backup and recovery, which is part of business continuity management.
However, only part of this task has been solved. The recovery time object (RTO), i.e. the target time that a recovery of IT and business activities may take, is too long for many companies with a pure backup & recovery solution.
Accordingly, it is common practice for many companies to distribute data centre capacities over two fire compartments, buildings, locations and to establish corresponding interconnects in order to be able to guarantee a fast switchover. This is sometimes a costly undertaking.
Faster and cost-saving: Azure Site Recovery
A cheaper and time-saving alternative is the Microsoft service "Azure Site Recovery". This also solves the problem. The interesting thing about the service is that all that is due is the data storage and a small fee per protected (virtual) machine.
The actual compute costs are only due in the event of a failover. The solution is shown in the following figure:
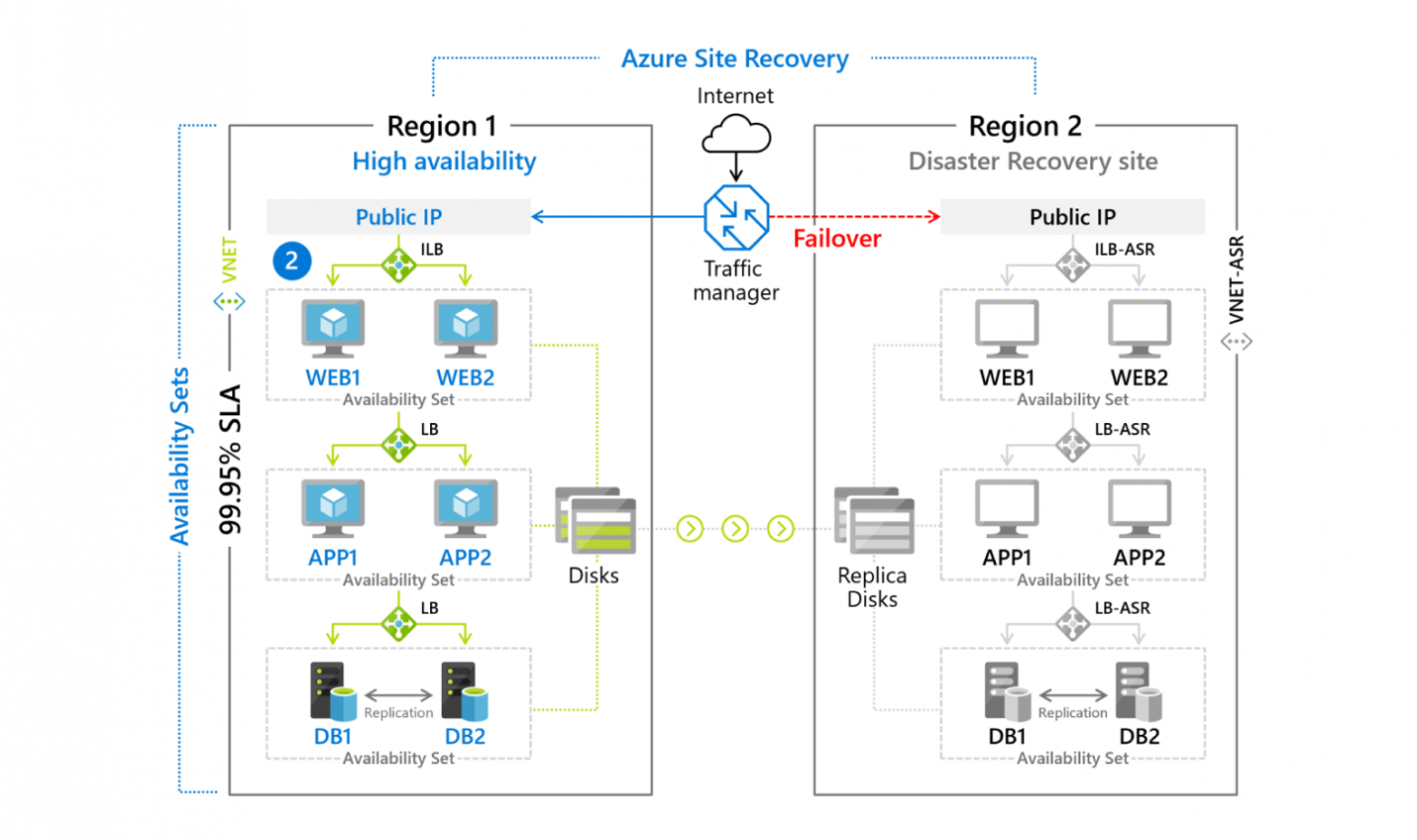
Source: "Azure Site Recovery", Microsoft, 2021
On the left side you see the productive data centre, which can run onpremises at your location, for example. The failover machines that become productive in the event of a controlled failover are shown on the right.
Depending on the hypervisor, data synchronisation can be set from synchronous to time cycles of 30 seconds to 15 minutes.

6 Advantages of Azure Site Recovery
Because of these six advantages, among others, we recommend a solution with Azure Site Recovery.
- Simplify BCDR
You can replicate, failover and recover multiple workloads from a single location in the Azure portal. Azure Site Recovery orchestrates the replication and failover.
- Flexible replication
You can replicate all workloads running on supported Hyper-V VMs, VMware VMs and physical Windows/Linux servers.
- Elimination of a secondary data centre
You can replicate workloads to Azure rather than a secondary site. This eliminates the cost and complexity of maintaining a secondary data centre. Replicated data is stored in Azure Storage with failover provided. When a failover occurs, Azure VMs are created with the replicated data.
- Perform simple replication tests
You can easily run test failovers to support disaster recovery scenarios without impacting production environments.
- Failover and Failback
You can perform scheduled failovers for expected failures with zero data loss or unscheduled failovers with minimal data loss (depending on replication frequency) for unexpected disasters. You can failback to your primary site when it becomes available again.
- Multiple VM failover
You can set up recovery plans that include scripts and Azure automation runbooks. Recovery plans allow you to model and customise failover and recovery of applications with multiple tiers distributed across multiple VMs.
Resource-saving and technically mature
As you can see, Azure Site Recovery is a cost-effective, resource-efficient and technically mature service that solves your business continuity requirements and has clear advantages over conventional solutions. In particular, the simplified possibility of carrying out test failovers and thus the possibility of steadily working your way towards a proven and functional failover convinced us to implement this service for our customers.

Your Contact
Do you have questions on this topic, would you like more information and are you looking for an expert to help you?
Contact us! We look forward to a successful cooperation with you.

Our partners
All partners





